안녕하세요. NVIDIA DLI 계속 진행하겠습니다.
1. NumPy Universal Functions(ufuncs)를 탑재한 GPU용 Numba 소개
GPU를 위한 NumPy Universal 함수(또는 ufuncs)를 컴파일하는 방법으로 Numba에서 GPU 프로그래밍을 시작할 것입니다.
GPU 프로그래밍을 시작하면서 알아야 할 가장 중요한 것은 GPU 하드웨어가 데이터 병렬화를 위해 설계되었다는 것입니다. GPU가 여러 다른 요소에서 동일한 연산을 한 번에 계산할 때 최대 처리량이 달성됩니다.
NumPy 배열의 모든 요소에서 동일한 연산을 수행하는 NumPy Universal 함수는 자연스럽게 데이터 병렬이므로 GPU 프로그래밍에 적합합니다.
1) GPU를 위한 ufuncs 만들기
Numba 는 컴파일된 ufuncs를 만드는 능력을 가지고 있는데, 일반적으로 C 코드를 포함하는 조금 어려운 프로세스입니다. 저는 C코드가 항상 어렵드라구요..파이썬으로 시작해서 그런가. Numba를 사용하면 모든 입력에 대해 수행할 스칼라 함수를 구현하고 @vectorize로 데코하면 Numba 가 broadcast rules을 계산해 줍니다.
즉, NumPy와 함께 사용되어 NumPy 배열을 효율적으로 처리하는 코드를 생성합니다. (스칼라+선형화(벡터))
NumPy의 벡터화에 익숙한 유저분이라면 Numba의 벡터화 데코레이터를 잘 사용할 거에요!
Ex1) @vectorize decorator를 사용하여 CPU의 ufunc를 컴파일하고 최적화해봅시다.
from numba import vectorize
import numpy as np
@vectorize
def add_ten(num):
return num + 10 # This scalar operation will be performed on each element
명시적인 타입의 시그니처를 부여하고 타겟 속성을 설정하는 추가로 GPU에서 CUDA를 사용하는 ufunc를 생성하고 있습니다. 타입 시그니처 인수는 ufuncs 인수와 리턴 값 둘 다에 어떤 타입을 사용할 것인지 설명합니다
Ex2) CUDA 지원 GPU 장치를 위해 컴파일될 ufunc의 간단한 예는 다음과 같습니다. 두 개의 int64 값과 int64 값을 기대합니다:
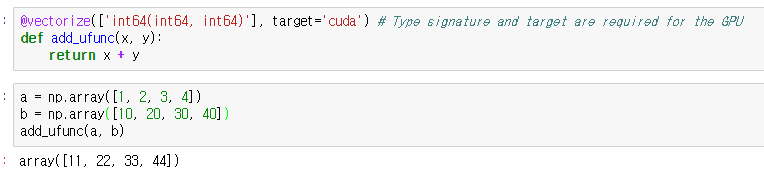
2) Numba 동작 순서
1. 모든 입력 요소에 대해 병렬로 ufunc 연산을 실행하기 위해 CUDA 커널 컴파일
2.입력 및 출력을 위해 GPU 메모리 할당
3.입력 데이터를 GPU에 복사
4.입력 크기가 주어진 올바른 커널 치수로 CUDA 커널(GPU 함수) 실행
5.GPU에서 CPU로 결과 다시 복사
6.호스트에서 결과를 NumPy 배열로 반환
Ex3) Numpy CPU vs Numba GPU

위 사례에서 GPU가 CPU보다 훨씬 느리다는 것을 알 수 있습니다. 그 이유로는
1) Input이 너무 작습니다.
GPU는 수천 개의 값에서 동시에 작동하는 병렬 처리를 통해 성능을 달성합니다. 우리의 테스트 입력은 각각 4개와 16개의 정수밖에 없습니다. GPU를 바쁘게 유지하려면 훨씬 더 큰 어레이가 필요합니다.
2) 계산이 너무 간단합니다.
GPU에 계산을 보내는 것은 CPU의 함수를 호출하는 것에 비해 상당한 오버헤드를 수반합니다. 계산에 충분한 연산(종종 "산술 강도"라고 함)이 포함되지 않으면 GPU는 데이터가 이동하기를 기다리며 대부분의 시간을 보낼 것입니다.
3) GPU로 데이터를 복사하고 GPU에서 데이터를 복사합니다.
일부 시나리오에서는 GPU로 데이터를 복사하는 비용을 지불하는 것이 단일 기능에 대한 가치가 있을 수 있지만 여러 GPU 작업을 순차적으로 실행하는 것이 선호됩니다. 이러한 경우 GPU로 데이터를 전송하고 모든 처리가 완료될 때까지 유지하는 것이 합리적입니다.
4) 우리의 데이터 Type은 필요 이상으로 큽니다.
32비트와 64비트 데이터 유형을 사용하는 스칼라 코드는 기본적으로 CPU에서 동일한 속도로 실행되며 정수 유형의 경우 차이가 급격하지 않을 수 있지만 64비트 부동 소수점 데이터 유형은 GPU 유형에 따라 상당한 성능 비용이 발생할 수 있습니다. 64비트 부동 소수점 데이터 유형의 기본 산술은 32비트 부동 소수점보다 2배에서 24배(맥스웰 아키텍처 지포스)까지 가능합니다. 더 최신 GPU(볼타, 튜링, 암페어)를 사용하는 경우에는 훨씬 덜 우려될 수 있습니다. 어레이를 생성할 때 NumPy는 기본적으로 64비트 데이터 유형이므로 dtype 속성을 설정하거나 ndarray.astype() 메서드를 사용하여 32비트 유형을 선택하는 것이 중요합니다.
(** 참고: 모든 NumPy 코드가 GPU에서 작동하는 것은 아니며, 다음 예와 같이 NumPy 코드 대신 수학 라이브러리의 pi와 exp를 사용해야 합니다.)
Ex 4) 따라서, 훨씬 더 큰 입력에서 훨씬 더 큰 연산을 수행하고 32비트 데이터 유형을 사용하여 GPU에서 더 빠른 예를 시도해 보겠습니다.
import math # Note that for the CUDA target, we need to use the scalar functions from the math module, not NumPy
SQRT_2PI = np.float32((2*math.pi)**0.5) # Precompute this constant as a float32. Numba will inline it at compile time.
@vectorize(['float32(float32, float32, float32)'], target='cuda')
def gaussian_pdf(x, mean, sigma):
'''Compute the value of a Gaussian probability density function at x with given mean and sigma.'''
return math.exp(-0.5 * ((x - mean) / sigma)**2) / (sigma * SQRT_2PI)import numpy as np
# Evaluate the Gaussian a million times!
x = np.random.uniform(-3, 3, size=1000000).astype(np.float32)
mean = np.float32(0.0)
sigma = np.float32(1.0)
# Quick test on a single element just to make sure it works
gaussian_pdf(x[0], 0.0, 1.0)

GPU에서 모든 데이터를 복사하는 오버헤드까지 포함하면 상당히 큰 향상입니다. 대규모 데이터 세트에서 특수 기능(exp, sin, cos 등)을 사용하는 Ufuncs는 GPU에서 특히 잘 실행됩니다.
@vectorize
def cpu_gaussian_pdf(x, mean, sigma):
'''Compute the value of a Gaussian probability density function at x with given mean and sigma.'''
return math.exp(-0.5 * ((x - mean) / sigma)**2) / (sigma * SQRT_2PI)
컴파일되지 않은 CPU 버전보다 훨씬 빠르지만 GPU가 가속한 버전보다는 훨씬 느립니다.
2. CUDA Device Functions
Ufuncs는 매우 일반적인 작업인 element별 작업을 수행하고 싶을 때 매우 유용합니다. element 적으로 벡터화된 함수가 아닌 GPU용 함수를 컴파일하려면 numba.cuda.jit를 사용합니다. 지금은 도우미 함수를 장식하는 데 사용하는 방법을 시연하여 GPU 가속 ufunc에서 사용하므로 모든 논리를 하나의 ufunc 정의에 주입할 필요가 없습니다.
아래의 polar_to_decartian은 형식 서명이 필요하지 않으며 NumPy 배열을 인수로 예상하는 벡터화된 ufunct(그리고 아래의 polar_distance와 유사)와 달리 두 개의 스칼라 값을 통과한다는 점에 주목해야합니다.
Ex 1) 인수 device=True는 장식된 함수가 CPU 호스트 코드가 아닌 GPU에서 실행되는 함수에서만 호출될 수 있음을 나타냅니다:
from numba import cuda
@cuda.jit(device=True)
def polar_to_cartesian(rho, theta):
x = rho * math.cos(theta)
y = rho * math.sin(theta)
return x, y
@vectorize(['float32(float32, float32, float32, float32)'], target='cuda')
def polar_distance(rho1, theta1, rho2, theta2):
x1, y1 = polar_to_cartesian(rho1, theta1) # We can use device functions inside our GPU ufuncs
x2, y2 = polar_to_cartesian(rho2, theta2)
return ((x1 - x2)**2 + (y1 - y2)**2)**0.5n = 1000000
rho1 = np.random.uniform(0.5, 1.5, size=n).astype(np.float32)
theta1 = np.random.uniform(-np.pi, np.pi, size=n).astype(np.float32)
rho2 = np.random.uniform(0.5, 1.5, size=n).astype(np.float32)
theta2 = np.random.uniform(-np.pi, np.pi, size=n).astype(np.float32)

CUDA 컴파일러는 공격적으로 장치 함수를 인라인하기 때문에, 함수 호출에 대한 오버헤드가 일반적으로 없습니다. 마찬가지로 polar_to_decartesic로 반환되는 "튜플"은 실제로는 파이썬 객체로 생성되지 않고 임시로 구조로 표현되며 컴파일러에 의해 최적화됩니다.
3. Allowed Python on the GPU
CPU의 Numba에 비해 GPU의 Numba는 제한이 많습니다. 지원되는 Python은 다음과 같습니다
- if/elif/else
- while and for loops
- Basic math operators
- math 모듈과 cmath 모듈의 선택적 기능
- Tuples
Ex1: GPU Accelerate a Function
zero suppression기능을 가속화 해보겠습니다. zero suppression(0 억제)기능이란 파형 작업을 할 때, 일반적으로 사용되는 연산은 낮은 진폭의 잡음을 제거하기 위해 특정 절대 크기 이하의 모든 샘플 값을 0으로 강제하는 것입니다. 샘플 데이터를 몇 가지 만들어 보겠습니다.
# This allows us to plot right here in the notebook
%matplotlib inline
# Hacking up a noisy pulse train
from matplotlib import pyplot as plt
n = 100000
noise = np.random.normal(size=n) * 3
pulses = np.maximum(np.sin(np.arange(n) / (n / 23)) - 0.3, 0.0)
waveform = ((pulses * 300) + noise).astype(np.int16)
plt.plot(waveform)
# This will throw an error until you successfully vectorize the `zero_suppress` function above.
# The noise on the baseline should disappear when zero_suppress is implemented
@vectorize(['int16(int16, int16)'], target='cuda')
def zero_suppress(waveform_value, threshold):
if waveform_value < threshold:
result = 0
else:
result = waveform_value
return result
plt.plot(zero_suppress(waveform, 15))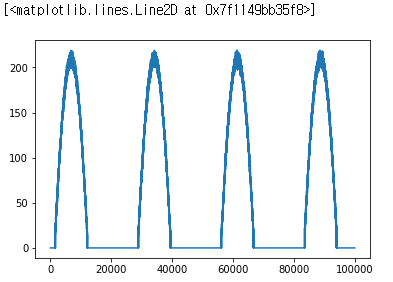
4. Managing GPU Memory
지금까지 우리는 CPU의 NumPy 배열을 우리의 GPU 기능에 대한 입력과 출력으로 사용했습니다. 편의상 Numba는 우리를 위해 이 데이터를 GPU에 자동으로 전송하여 GPU에서 작동할 수 있도록 하고 있습니다.
이 암묵적인 데이터 전송으로 Numba는 보수적으로 행동하면 처리 후에 데이터를 CPU로 자동으로 다시 전송할 것입니다.
High Priority: 호스트 CPU에서 커널을 실행할 때와 비교할 때, 성능 향상이 나타나지 않는 일부 커널을 디바이스에서 실행하는 것을 의미하더라도 호스트와 디바이스 간의 데이터 전송을 최소화합니다.
이를 염두에 두고 이러한 자동 데이터가 호스트로 다시 전송되는 것을 방지하여 데이터에 대한 추가 작업을 수행할 수 있는 방법을 고려해야 하며, 이는 진정한 준비가 되었을 때 호스트로 다시 복사하는 비용만 지불해야 합니다.
예를 들어, 예제 덧셈 ufunc을 다시 만들어 보겠습니다.
@vectorize(['float32(float32, float32)'], target='cuda')
def add_ufunc(x, y):
return x + yn = 100000
x = np.arange(n).astype(np.float32)
y = 2 * x
numba.cuda 모듈에는 호스트 데이터를 GPU에 복사하고 CUDA 디바이스 어레이를 반환하는 기능이 포함되어 있습니다. 아래에서는 디바이스 어레이의 내용을 인쇄하려고 할 때 어레이에 대한 정보만 얻을 뿐 실제 내용은 얻을 수 없습니다. 데이터가 디바이스에 있기 때문에 값을 인쇄하기 위해서는 호스트에 다시 전송해야 하기 때문인데, 이 작업은 나중에 보여드리겠습니다:
from numba import cuda
x_device = cuda.to_device(x)
y_device = cuda.to_device(y)
print(x_device)
print(x_device.shape)
print(x_device.dtype)Device array는 NumPy 어레이와 마찬가지로 CUDA 기능으로 전달할 수 있지만, 복사 오버헤드는 없습니다.

x_device와 y_device가 이미 디바이스에 있기 때문에 이 벤치마크는 훨씬 빠릅니다.
그러나 위의 셀에서 실제로 배열을 변수에 할당하지는 않지만 여전히 ufunc의 출력을 위해 장치 배열을 할당하고 호스트에 다시 복사하고 있습니다. 이를 방지하기 위해 numba.cuda.device_array() 함수를 사용하여 출력 배열을 만들 수 있습니다:
out_device = cuda.device_array(shape=(n,), dtype=np.float32) # does not initialize the contents, like np.empty()그런 다음 ufunc에 특별한 out 키워드 인수를 사용하여 출력 버퍼를 지정할 수 있습니다.

이 add_ufunc 호출은 호스트와 디바이스 간의 데이터 전송을 수반하지 않으므로 가장 빠르게 실행됩니다. 디바이스 어레이를 호스트 메모리로 되돌리고 싶을 때 copy_to_host() 메서드를 사용할 수 있습니다:
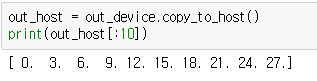
암묵적인 데이터 전송이 호스트 어레이 a와 b를 사용할 때 벤치마킹 쪽으로 계산되고 있지만 디바이스 어레이를 사용할 때 to_device 호출을 벤치마킹하지 않았기 때문에 여기서는 사과와 사과를 비교하지 않는다고 생각할 수 있습니다. 물론 앞서 설명한 것처럼 우리의 add_func 함수는 GPU에 특별히 적합하지 않습니다. 위의 내용은 전송을 제거하는 방법을 설명하기 위한 것일 뿐입니다.
GPU로의 이동이 가치가 있는지 여부를 조사할 때는 데이터 전송을 벤치마킹해야 합니다.
또한 Numba는 장치 메모리 및 데이터 전송을 관리하기 위한 추가 방법을 제공합니다. 자세한 내용은 문서를 확인하세요!
'Computer Science > NVIDIA' 카테고리의 다른 글
| GPU Architecture (0) | 2023.12.21 |
|---|---|
| GPU란 무엇인가 (0) | 2023.12.17 |
| 2-1 Fundamentals of Accelerated Computing with CUDA Python (0) | 2023.12.16 |
| 1-1 Fundamentals of Accelerated Computing with CUDA Python (0) | 2023.12.14 |
| CUDA란 무엇인가 (0) | 2023.12.14 |


