안녕하세요. 진또배기입니다.
이번엔 해당 교육의 2번째 챕터인
Custom CUDA Kernels in Python with Numba
에 대해 공부하는 시간을 갖겠습니다~😊
이 섹션에서는 CUDA 프로그래밍 모델이 병렬 작업을 구성하는 방법에 대해 더 자세히 알아보고, 이러한 이해를 활용하여 CUDA GPU에서 병렬로 실행되는 기능인 사용자 지정 CUDA 커널을 작성할 것입니다. 사용자 지정 CUDA 커널은 CUDA 프로그래밍 모델을 활용할 때 단순히 @vectorize로 ufunc를 장식하는 것보다 구현하는 데 더 많은 작업이 필요합니다. 그러나 ufunc가 불가능한 곳에서는 병렬 컴퓨팅을 가능하게 하고 최고 수준의 성능으로 이어질 수 있는 유연성을 제공합니다.
정리하면, 우리가 이번 챕터에서 배우는 것은,
- Python에 커스텀 CUDA 커널 작성 역량
- 그리드 스트라이드 루프를 활용하여 대규모 데이터 세트에서 병렬로 작업하고 메모리 병합을 활용
- 병행 작업 시 race 조건을 피하기 위해 원자 연산을 사용
1. Custom Kernels의 필요성
Custom CUDA 커널을 작성하는 것은 GPU 가속 ufunc를 작성하는 것보다 더 어려운 일이지만, 개발자들은 GPU에서 병렬로 실행하기 위해 보낼 수 있는 함수의 종류에 대해 엄청난 유연성을 제공합니다. 또한 이 섹션과 다음 섹션에서 학습을 시작할 때 개발자들에게 CUDA의 스레드 계층 구조를 명시적으로 노출함으로써 병렬이 수행되는 방식에 대한 세밀한 제어를 제공합니다.
오직 파이썬에만 머무르면서도 Numba를 사용하여 CUDA 커널을 작성하는 방식은 개발자가 CUDA C/C++로 작성하는 방식을 매우 연상시킵니다. CUDA C/C++로 프로그래밍하는 것에 익숙한 분들은 Numba를 사용하여 파이썬에서 사용자 지정 커널을 매우 빠르게 픽업할 수 있으며, 처음 배우는 분들은 여기에서 수행하는 작업이 CUDA를 C/C++로 개발해야 하거나 CUDA C/C++ 코드를 가장 일반적으로 묘사하는 웹상의 CUDA 리소스의 풍부함을 연구해야 하는 경우에도 도움이 됩니다.
2. CUDA Kernels 소개
CUDA로 프로그래밍할 때 개발자가 실행되는 커널, 즉 CUDA 용어로 실행되는 커널이라는 GPU를 위한 함수를 병렬 스레드에 있는 GPU의 많은 코어에 씁니다. 커널이 실행되면 프로그래머들은 병렬 실행의 구성을 설명하기 위해 실행 구성(실행 구성이라고도 함)이라고 불리는 특수 구문을 사용합니다.
다음 슬라이드는 CUDA 커널이 GPU 장치에서 대규모 데이터 세트에서 병렬로 작동하도록 생성되는 방법에 대한 높은 수준의 설명을 제공합니다. 슬라이드를 통해 작업한 다음 슬라이드에 제시된 아이디어를 사용하여 자신만의 맞춤형 CUDA 커널을 작성하고 실행하기 시작합니다.
(슬라이드 생략)
먼저 1D NumPy 배열에 대한 추가 기능을 다시 작성하여 구체적이고 매우 간단한 예부터 시작하겠습니다. CUDA 커널은 numba.cuda.jit decorator를 사용하여 컴파일됩니다. numba.cuda.jit은 CPU의 기능을 최적화하는 것을 이미 배운 numba.jit decorator와 혼동하지 마세요!
from numba import cuda
# 'out' 배열의 사용에 주의해야합니다. '@cuda.jit'로 쓰여진 CUDA 커널은 값을 반환하지 않습니다.
# C와 마찬가지로 @cuda.jit에는 명시적인 형식의 서명이 필요하지 않습니다
def add_kernel(x, y, out):
# 스레드 및 블록 지수에 대한 다음 CUDA 제공 변수의 실제 값,
# 함수 매개변수와 마찬가지로 커널이 실행될 때까지 알 수 없습니다.
# 이 계산은 전체 그리드 내에서 고유한 스레드 인덱스를 제공합니다
idx = cuda.grid(1) # 1 = 1차원 스레드 그리드, 단일 값을 반환합니다.
# 이 Numba 제공 편의 기능은 아래와 같습니다
# `cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x`
# 이 스레드는 자체 인덱스와 동일한 데이터 요소에 대한 작업을 수행합니다
# 그리드 내의 고유 인덱스입니다.
out[idx] = x[idx] + y[idx]import numpy as np
n = 4096
x = np.arange(n).astype(np.int32) # [0...4095] on the host
y = np.ones_like(x) # [1...1] on the host
d_x = cuda.to_device(x) # Copy of x on the device
d_y = cuda.to_device(y) # Copy of y on the device
d_out = cuda.device_array_like(d_x) # Like np.array_like, but for device arrays
# 위에 커널을 작성한 방법 때문에 1개의 스레드에서 1개의 데이터 요소 매핑이 필요합니다,
# 따라서 그리드의 스레드 수(128*32)를 n(4096)과 같게 정의합니다.
threads_per_block = 128
blocks_per_grid = 32
3. An Aside on Hiding Latency and Execution Configuration Choices
CUDA 지원 NVIDIA GPU는 DRAM이 연결된 여러 Streaming MultiProcessor 또는 SM으로 구성됩니다. SM에는 많은 CUDA 코어를 포함하여 커널 코드 실행에 필요한 모든 리소스가 포함되어 있습니다. 커널이 시작되면 각 블록은 하나의 SM에 할당되며, 잠재적으로 많은 블록이 하나의 SM에 할당됩니다. SM은 블록을 32개 스레드의 추가 하위 분할인 와프(warp)로 분할하며, 이와 같은 와프는 병렬 실행 명령을 받습니다.
명령어가 완료(또는 CUDA 용어로, 만료)되는 데 두 번 이상의 클럭 사이클이 필요할 때, SM은 새로운 명령어를 발행할 준비가 된 추가 워프가 있으면 의미 있는 작업을 계속 수행할 수 있습니다. SM의 매우 큰 레지스터 파일 때문에 SM이 명령어를 발행하는 사이의 컨텍스트를 한 워프 또는 다른 워프로 변경하는 데 시간 패널티가 없습니다. 간단히 말해서, 다른 작업이 수행되는 한 다른 의미 있는 작업으로 SM은 작업의 지연 시간을 숨길 수 있습니다.
따라서 GPU의 잠재력을 최대한 활용하여 성능이 뛰어난 가속 애플리케이션을 작성하는 것이 가장 중요하며, SM에 충분한 수의 와프를 제공하여 지연 시간을 숨길 수 있는 기능을 제공하는 것이 필수적이며, 이는 충분히 큰 그리드 및 블록 치수의 커널을 실행함으로써 가장 간단하게 달성할 수 있습니다.
CUDA 스레드 그리드에 가장 적합한 크기를 결정하는 것은 복잡한 문제이며, 알고리즘과 특정 GPU의 계산 능력에 따라 달라집니다. 하지만 여기에는 시작하는 데 적합한 직관적 방식이 있습니다.
- 블록의 크기는 32개의 스레드의 배수(워프 크기)여야 하며 일반적인 블록 크기는 블록당 128개에서 512개 사이입니다.
- 그리드의 크기는 가능한 한 풀 GPU를 활용하도록 보장해야 합니다. GPU에서 SM의 수보다 블록의 수가 2배-4배 많은 그리드를 시작하는 것이 좋습니다. 일반적으로 20-100 블록 범위의 것이 좋은 시작점입니다.
- CUDA 커널 런칭 오버헤드는 블록의 수에 따라 증가하므로, 입력 크기가 매우 클 때 우리는 스레드 수가 입력 요소의 수와 동일한 곳에서 그리드를 런칭하지 않는 것이 가장 좋습니다. 그 대신에 우리는 이제 큰 입력을 처리하는 데 관심을 돌릴 패턴을 사용합니다.
4. Grid Stride Loop
위의 add_kernel을 리팩터하여 그리드 스트라이드 루프를 활용하여 더 큰 데이터 세트에서 유연하게 작동할 수 있도록 시작하는 동시에 병렬 스레드가 연속 청크에서 메모리에 액세스할 수 있도록 하는 글로벌 메모리 병합의 이점을 얻을 수 있습니다. 이 시나리오를 통해 GPU가 총 메모리 작업 수를 줄일 수 있습니다.
from numba import cuda
@cuda.jit
def add_kernel(x, y, out):
start = cuda.grid(1)
# This calculation gives the total number of threads in the entire grid
stride = cuda.gridsize(1) # 1 = one dimensional thread grid, returns a single value.
# This Numba-provided convenience function is equivalent to
# `cuda.blockDim.x * cuda.gridDim.x`
# 이 스레드는 자체 데이터 요소 인덱스와 동일한 데이터 요소 인덱스에서 작업을 시작합니다
# 그리드의 고유 인덱스를 표시하면 그리드의 스레드 수가 각각 증가합니다
# 데이터의 한계를 벗어나지 않는 한 반복합니다. 이런 식으로 각
# 스레드는 둘 이상의 데이터 요소에서 작동할 수 있으며, 모든 스레드는 함께 작동합니다
# 모든 데이터 요소.
for i in range(start, x.shape[0], stride):
# x와 y 입력의 길이가 동일하다고 가정합니다
out[i] = x[i] + y[i]import numpy as np
n = 100000 # This is far more elements than threads in our grid
x = np.arange(n).astype(np.int32)
y = np.ones_like(x)
d_x = cuda.to_device(x)
d_y = cuda.to_device(y)
d_out = cuda.device_array_like(d_x)
threads_per_block = 128
blocks_per_grid = 30
1) Single Threaded on the Device
그냥 예시로, 단 하나의 스레드가 있는 그리드에서 커널을 시작해 보겠습니다. 여기서는 측정값이 CUDA 커널 큐의 유한한 깊이에 영향을 받지 않도록 하기 위해 문장을 한 번만 실행하는 %time을 사용하겠습니. 커널이 완료되기 전에 CPU로 제어를 반환하기 때문에 부적절한 시간이 발생하지 않도록 cuda.synchronize도 추가할 것입니다:

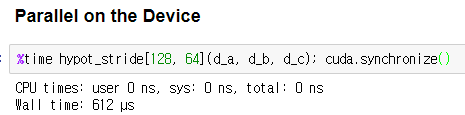
기본 CPU 실행 속도보다 훨씬 느리다는 점을 알 수 있습니다.
5. Atomic Operations and Avoiding Race Conditions
CUDA는 많은 범용 병렬 실행 프레임워크와 마찬가지로 코드 내에 레이스 조건이 있는 것을 가능하게 합니다. CUDA에서 레이스 조건은 스레드가 다른 독립 스레드에 의해 수정될 수도 있는 메모리 위치를 읽거나 기록할 때 발생합니다. 일반적으로 다음 사항을 고려해야 합니다.
- read-after-write hazards
하나의 스레드는 메모리 위치를 읽는 동시에 다른 스레드가 메모리 위치에 쓸 수 있습니다. - write-after-write hazards
두 개의 스레드가 동일한 메모리 위치에 기록되고 있으며 커널이 완료되면 한 개의 기록만 볼 수 있습니다.
이러한 두 가지 위험을 모두 피하기 위한 일반적인 전략은 CUDA 커널 알고리즘을 구성하여 각 스레드가 출력 어레이 요소의 고유한 하위 집합에 대해 독점적인 책임을 갖도록 하고/하거나 단일 커널 호출에서 입력과 출력 모두에 대해 동일한 어레이를 사용하지 않도록 하는 것입니다. (반복 알고리즘은 필요한 경우 이중 버퍼링 전략을 사용할 수 있으며 각 반복에서 입력과 출력 어레이를 전환할 수 있습니다.)
하지만 다른 스레드가 결과를 결합해야 하는 경우가 많습니다. "모든 스레드가 전역 카운터를 증가시킵니다."와 같은 매우 간단한 것을 생각해 보세요. 커널에 이를 구현하려면 각 스레드가 다음 작업을 수행해야 합니다:
1. 글로벌 카운터의 현재 값을 읽습니다.
2. Compute counter + 1.
3. 해당 값을 글로벌 메모리에 다시 기록합니다.
그러나 1단계와 3단계 사이의 전역 카운터가 다른 스레드에 의해 변경되지 않았다는 보장은 없습니다. 이 문제를 해결하기 위해 CUDA는 분할할 수 없는 하나의 단계에서 메모리 위치를 읽고 수정 및 업데이트하는 원자 연산을 제공합니다. 여기에 설명된 이러한 기능 중 몇 가지를 Numba가 지원합니다.
스레드 카운터 커널을 만들어 보겠습니다.
@cuda.jit
def thread_counter_race_condition(global_counter):
global_counter[0] += 1 # This is bad
@cuda.jit
def thread_counter_safe(global_counter):
cuda.atomic.add(global_counter, 0, 1) # lobal_counter 배열에서 offset 0에 1을 안전하게 더합니다아래는 잘못된 답을 얻습니다.
global_counter = cuda.to_device(np.array([0], dtype=np.int32))
thread_counter_race_condition[64, 64](global_counter)
print('Should be %d:' % (64*64), global_counter.copy_to_host())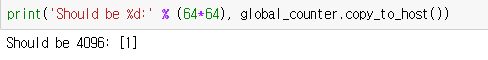
아래가 올바른 정답입니다.
global_counter = cuda.to_device(np.array([0], dtype=np.int32))
thread_counter_safe[64, 64](global_counter)
print('Should be %d:' % (64*64), global_counter.copy_to_host())
'Computer Science > NVIDIA' 카테고리의 다른 글
| GPU Architecture (0) | 2023.12.21 |
|---|---|
| GPU란 무엇인가 (0) | 2023.12.17 |
| 1-2 Fundamentals of Accelerated Computing with CUDA Python (0) | 2023.12.16 |
| 1-1 Fundamentals of Accelerated Computing with CUDA Python (0) | 2023.12.14 |
| CUDA란 무엇인가 (0) | 2023.12.14 |



