안녕하세요. 진또배기입니다.
이번엔 해당 교육의 3번째 챕터인
Effective Use of the Memory Subsystem
에 대해 공부하는 시간을 갖겠습니다~😊
우리가 지난 시간에 연구한 것은 CUDA커널을 작성역량과 GPU에 대기 시간을 줄일 수 있는 Grid 실행역량입니다.
이를 기반으로, GPU의 Subsystem을 효과적으로 활용하는 기술에 대해 배우겠습니다!
위 기술은 CUDA 애플리케이션에 널리 적용 가능하며, CUDA 코드를 빠르게 만들 때 가장 중요한 기술 중 일부입니다.
정리하면,
1. 메모리 병합(memory coalescing)
2. 2차원 Grid 및 Thread 블록 작
3. 공유 메모리(사용자 제어 온디맨드 메모리 공간)의 사용
4. 공유 메모리 Bank 충돌과 이를 해결할 수 있는 기술
에 대해 배우겠습니다.
1. 통합되지 않은 메모리 액세스로 인한 성능저하
통합 메모리 액세스가 무엇인지 알아보기 전에,
아래 코드를 실행해 커널 내 데이터 액세스 패턴에 대한 쪼끄만 변경이 성능에 미치는 영향에 대해 알아봅시다.
1) Import
import numpy as np
from numba import cuda
2) Data 생성
아래 셀에서 n을 정의하고 n과 동일한 스레드가 있는 그리드를 만듭니다. 또한 길이가 n인 출력 벡터를 만듭니다. Input 벡터로 stride * n 크기의 벡터를 생성합니다.
n = 1024*1024 # 1M
threads_per_block = 1024
blocks = int(n / threads_per_block)
stride = 16
# Input 벡터 = stride * n 크기의 벡터를 생성
a = np.ones(stride * n).astype(np.float32)
b = a.copy().astype(np.float32)
# Output 벡터
out = np.zeros(n).astype(np.float32)
d_a = cuda.to_device(a)
d_b = cuda.to_device(b)
d_out = cuda.to_device(out)
3) Kernel 정의
add_experiment에서 그리드의 모든 스레드는 a의 항목과 b의 항목을 추가하고 결과를 out에 기록합니다.
커널은 a 및 b 벡터에 대한 인덱싱 방법에 영향을 주기 위해 True 또는 False의 병합된 값을 전달할 수 있도록 작성되었습니다. 아래 두 모드의 성능 비교를 볼 수 있습니다.
@cuda.jit
def add_experiment(a, b, out, stride, coalesced):
i = cuda.grid(1)
# 위 라인은 아래 항목과 같은 뜻입니다.
# i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
if coalesced == True:
out[i] = a[i] + b[i]
else:
out[i] = a[stride*i] + b[stride*i]
EX1) 통합된 액세스를 사용 커널 시작
- 통합된 값으로 True를 전달하고 여러 실행에 걸쳐 커널의 성능을 관찰합니다.

커널이 예상대로 실행되었는지 확인해봅시다.

EX2) 통합되지 않은 액세스를 사용한 커널 시작
- 통합되지 않은 데이터 액세스 패턴의 성능을 관찰하기 위해 False 입력.

커널이 예상대로 실행되었는지 확인해봅시다.
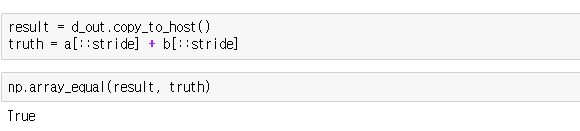
통합되지 않은 데이터 액세스 패턴의 성능은 훨씬 안좋습니다. 이제 고성능 커널을 얻기 위해 커널의 데이터 액세스 패턴에 대해 생각하는 이유와 방법을 배워봅시다.
2. Exercise: Column and Row Sums
아래 exercise는 통합된 메모리 액세스 패턴을 사용하는 열 합계 커널을 작성하라는 요청입니다.
연습문제 1) Row Sums
a. Import
import numpy as np
from numba import cudab. Data 생성
n = 16384 # matrix side size
threads_per_block = 256
blocks = int(n / threads_per_block)
# Input 매트릭스
a = np.ones(n*n).reshape(n, n).astype(np.float32)
# 아래의 정확성을 쉽게 확인할 수 있도록 임의의 행을 임의의 값으로 설정
a[3] = 9
# Output vector
sums = np.zeros(n).astype(np.float32)
d_a = cuda.to_device(a)
d_sums = cuda.to_device(sums)
c. Kernel 정의
row_sums는 각 스레드를 사용하여 데이터 행을 반복하고 합한 다음, 해당 행 합계를 합계에 저장
@cuda.jit
def row_sums(a, sums, n):
idx = cuda.grid(1)
sum = 0.0
for i in range(n):
# 각 스레드는 'a'스레드를 합산합니다.
sum += a[idx][i]
sums[idx] = sum
d. Row Sums 성능 확인

e. 정확도 체크
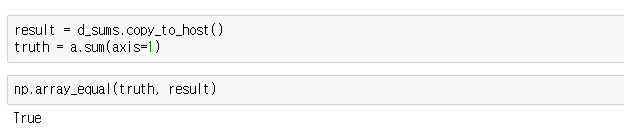
연습문제 2) Column Sums
a. import
import numpy as np
from numba import cuda
b. Data 생성
Input 매트릭스와 솔루션을 저장하기 위한 벡터를 생성.
Kernel을 시작할 때 사용할 그리드 및 블록 크기 정의.
정확성 확인을 위한 데이터 column을 임의의 값으로 설정.
n = 16384 # matrix side size
threads_per_block = 256
blocks = int(n / threads_per_block)
a = np.ones(n*n).reshape(n, n).astype(np.float32)
# 확성을 쉽게 확인할 수 있도록 임의의 열을 임의의 값으로 설정함.
a[:, 3] = 9
sums = np.zeros(n).astype(np.float32)
d_a = cuda.to_device(a)
d_sums = cuda.to_device(sums)
c. Kernel 정의
col_sums는 각 스레드를 사용하여 데이터 열을 반복하고 합계를 낸 다음, 해당 열 합계를 합계에 저장.
@cuda.jit
def col_sums(a, sums, ds):
# TODO: 행렬 `a`의 각 열의 합을 `sums` 벡터에 저장하려면 이 커널을 작성하세요.
pass
d. 성능확인
병합된 액세스 패턴을 사용하기 위해 col_sum을 작성했다고 가정하면, 위에서 실행한 병합되지 않은 row_sum에 비해 속도가 크게(거의 2배) 향상되는 것을 볼 수 있습니다.

e. 정확도 체크
커널이 예상대로 작동되는지 확인 --> False
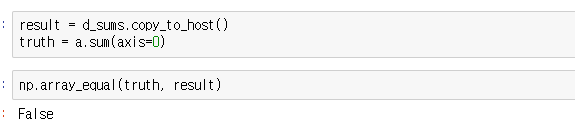
지금까지 병합 액세스 패턴(Row sums)과 병합되지 않은 액세스 패턴(Column sums)의 속도차이에 대해 알아보았습니다.
이제 2차원, 3차원 데이터 세트에 대한 작업에 대해 알아보겠습니다.
3. 2차원 및 3차원의 블록과 그리드
그리드와 블록 모두 각각 블록이나 스레드의 2차원 또는 3차원 컬렉션을 포함하도록 구성할 수 있습니다. 이는 주로 2차원 또는 3차원 데이터 세트로 작업하는 프로그래머의 편의를 위해 수행됩니다. 다음은 구문을 강조하는 매우 간단한 예입니다.
import numpy as np
from numba import cuda
A = np.zeros((4,4)) # A 4x4 Matrix of 0's
d_A = cuda.to_device(A)
# 2x2 구조에 4개의 블록이 있는 2D 그리드를 생성합니다.
# 각 블록에는 2x2 구조에 4개의 스레드가 있습니다.
# Python 튜플을 사용하여 그리드 및 블록 크기를 정한다.
blocks = (2, 2)
threads_per_block = (2, 2)
이 커널은 0행렬을 사용하여 각 요소에 X.Y 형식으로 그리드 내의 (x,y) 좌표를 씁니다.
@cuda.jit
def get_2D_indices(A):
# `2`를 전달하면 2D 그리드에서 스레드의 고유한 x 및 y 좌표를 얻습니다.
x, y = cuda.grid(2)
# 위 코드는 다음 두 줄의 코드와 같습니다:
# x = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
# y = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
# x 인덱스를 쓰고 그 뒤에 소수점과 y 인덱스를 씁니다.
A[x][y] = x + y / 10get_2D_indices[blocks, threads_per_block](d_A)result = d_A.copy_to_host()
result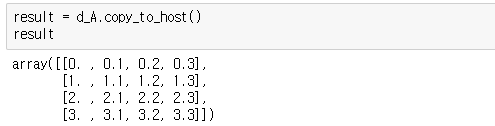
연습문제 1) Coalesced 2차원 행렬 더하기
Coalesced 의 의미를 간단하게 설명하면,
한 워프가 요구하는 메모리가 뭉쳐있어 글로벌 메모리에서 캐시에 복사하여 올리거나, 캐시의 변경된 내용을 글로벌 메모리에 쓰기 좋다는 뜻입니다.
1) Import
import numpy as np
from numba import cuda
2) Data Creation
이 셀에서는 2048x2048 요소 입력 행렬 a 및 b와 2048x2048크기의 0 초기화 출력 행렬을 정의합니다. 이러한 행렬을 장치에 복사합니다.
또한 아래에서 사용할 2차원 블록 및 그리드 치수를 정의합니다. 입력 및 출력 요소가 있는 것과 동일한 수의 총 스레드로 그리드를 생성하므로 그리드의 각 스레드가 출력 행렬의 단일 요소에 대한 합계를 계산합니다.
n = 2048*2048 # 4M
# 2D blocks
threads_per_block = (32, 32)
# 2D grid
blocks = (64, 64)
# 2048x2048 입력 매트릭스
a = np.arange(n).reshape(2048,2048).astype(np.float32)
b = a.copy().astype(np.float32)
# 2048x2048 0초기화 행렬
out = np.zeros_like(a).astype(np.float32)
d_a = cuda.to_device(a)
d_b = cuda.to_device(b)
d_out = cuda.to_device(out)
3) 2D Matrix Add
이 연습문제의 미션은 a와 b를 정확하게 합산하여 out으로 만들기 위해 Matrix_add의 TODO를 완료하는 것입니다. coalesced access patterns의 이해를 위해, matrix_add는 액세스 패턴을 통합해야 하는지 여부를 나타내는 coalesced boolean을 허용합니다. 두 모드 (coalesced and uncoalesced) 모두 올바른 결과를 생성해야 하지만, coalesced 을 True로 설정하여 실행하면 아래에서 상당한 속도 향상을 볼 수 있습니다.
@cuda.jit
def matrix_add(a, b, out, coalesced):
# TODO: set x and y to index correctly such that each thread
# accesses one element in the data.
x, y = cuda.grid(2) # pass
if coalesced == True:
# TODO: write the sum of one element in `a` and `b` to `out`
# using a coalesced memory access pattern
out[y][x] = a[y][x] + b[y][x]
else:
# TODO: write the sum of one element in `a` and `b` to `out`
# using an uncoalesced memory access pattern.
out[x][y] = a[x][y] + b[x][y]
4) 성능측정
아래의 두 셀을 모두 실행하여 작성한 coalesced and uncoalesced access patterns 을 모두 사용하여 matrix_add를 실행하고 성능 차이를 관찰해봅시다. 커널의 정확성을 확인하기 위해 추가 셀이 제공되었습니다.




'Computer Science > NVIDIA' 카테고리의 다른 글
| vGPU 실습2 (0) | 2024.02.23 |
|---|---|
| vGPU 실습1 (0) | 2024.02.21 |
| GPU Architecture (0) | 2023.12.21 |
| GPU란 무엇인가 (0) | 2023.12.17 |
| 2-1 Fundamentals of Accelerated Computing with CUDA Python (0) | 2023.12.16 |



